
1.2.5. Первичный ключ
Мы уже достаточно много говорили про ключевые поля, но ни разу их не использовали. Самое интересное, что все работало. Это преимущество, а может недостаток базы данных Microsoft SQL Server и MS Access. В таблицах Paradox такой трюк не пройдет и без наличия ключевого поля таблица будет доступна только для чтения.
В какой-то степени ключи являются ограничениями, и их можно было рассматривать вместе с оператором CHECK, потому что объявление происходит схожим образом и даже используется оператор CONSTRAINT. Давайте посмотрим на этот процесс на примере. Для этого создадим таблицу из двух полей «guid» и «vcName». При этом поле «guid» устанавливается как первичный ключ:
CREATE TABLE Globally_Unique_Data ( guid uniqueidentifier DEFAULT NEWID(), vcName varchar(50), CONSTRAINT PK_guid PRIMARY KEY (Guid) )
Самое вкусное здесь это строка CONSTRAINT. Как мы знаем, после этого ключевого слова идет название ограничения, и объявления ключа не является исключением. Для именования первичного ключа, я рекомендую использовать именование типа PK_имя, где имя – это имя поля, которое должно стать главным ключом. Сокращение PK происходит от Primary Key (первичный ключ).
После этого, вместо ключевого слова CHECK, которое мы использовали в ограничениях, стоит оператор PRIMARY KEY, Именно это указывает на то, что нам необходима не проверка, а первичный ключ. В скобках указывается одно, или несколько полей, которые будут составлять ключ.
Помните, что в ключевом поле не может быть одинакового значения у двух строк, в этом ограничение первичного ключа идентично ограничению уникальности. Это значит, что если сделать поле для хранения фамилии первичным ключом, то в такую таблицу нельзя будет записать двух Ивановых с разными именами. Это нарушает ограничение первичного ключа. Именно поэтому ключи являются ограничениями и объявляются также как и ограничение CHECK. Но это не верно только для первичных ключей и вторичных с уникальностью.
В данном примере, в качестве первичного ключа выступает поле типа uniqueidentifier (GUID). Значение по умолчанию для этого поля – результат выполнения серверной процедуры NEWID.
Внимание
Только один первичный ключ может быть создан для таблицы
Для простоты примеров, в качестве ключа желательно использовать численный тип и если позволяет база данных, то будет лучше, если он будет типа «autoincrement» (автоматически увеличивающееся/уменьшающееся число). В MS SQL Server таким полем является IDENTITY, а в MS Access это поле типа «счетчик».
Следующий пример показывает, как создать таблицу товаров, в которой в качестве первичного ключа выступает целочисленное поле с автоматическим увеличением:
CREATE TABLE Товары ( id int IDENTITY(1, 1), товар varchar(50), Цена money, Количество numeric(10, 2), CONSTRAINT PK_id PRIMARY KEY (id) )
Именно такой тип ключа мы будем использовать чаще всего, потому что в ключевом поле будут храниться легкие для восприятия числа и с ними проще и нагляднее работать.
Первичный ключ может состоять из более, чем одной колонки. Следующий пример создает таблицу, в которой поля «id» и «Товар» образуют первичный ключ, а значит, будет создан индекс уникальности на оба поля:
CREATE TABLE Товары1
(
id int IDENTITY(1, 1),
Товар varchar(50),
Цена money,
Количество numeric(10, 2),
CONSTRAINT PK_id PRIMARY KEY
(id, )
)
Очень часто программисты создают базу данных с ключевым полем в виде целого числа, но при этом в задаче четко стоит, что определенные поля должны быть уникальными. А почему не создать сразу первичный ключ из тех полей, которые должны быть уникальны и не надо будет создавать отдельные решения для данной проблемы.
Единственный недостаток первичного ключа из нескольких колонок – проблемы создания связей. Тут приходиться выкручиваться различными методами, но проблема все же решаема. Достаточно только ввести поле типа uniqueidentifier и производить связь по нему. Да, в этом случае у нас получаются уникальными первичный ключ и поле типа uniqueidentifier, но эта избыточность в результате не будет больше, чем та же таблица, где первичный ключ uniqueidentifier, а на поля, которые должны быть уникальными установлено ограничение уникальности. Что выбрать? Зависит от конкретной задачи и от того, с чем вам удобнее работать.
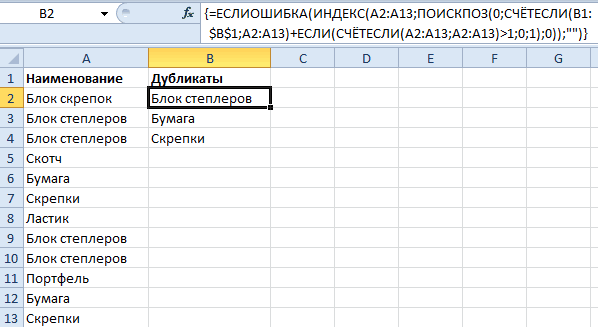
Duplicate Remover — быстрый и эффективный способ найти дубликаты в Excel
Теперь, когда вы знаете, как использовать формулы для поиска повторяющихся значений в Excel, позвольте мне продемонстрировать вам еще один быстрый, эффективный и без всяких формул способ: инструмент Duplicate Remover для Excel.
Этот универсальный инструмент может искать повторяющиеся или уникальные значения в одном столбце или же сравнивать два столбца. Он может находить, выбирать и выделять повторяющиеся записи или целые повторяющиеся строки, удалять найденные дубли, копировать или перемещать их на другой лист. Я думаю, что пример практического использования может заменить очень много слов, так что давайте перейдем к нему.
Как найти повторяющиеся строки в Excel за 2 быстрых шага
Сначала посмотрим в работе наиболее простой инструмент — быстрый поиск дубликатов Quick Dedupe. Используем уже знакомую нам таблицу, в которой мы выше искали дубликаты при помощи формул:
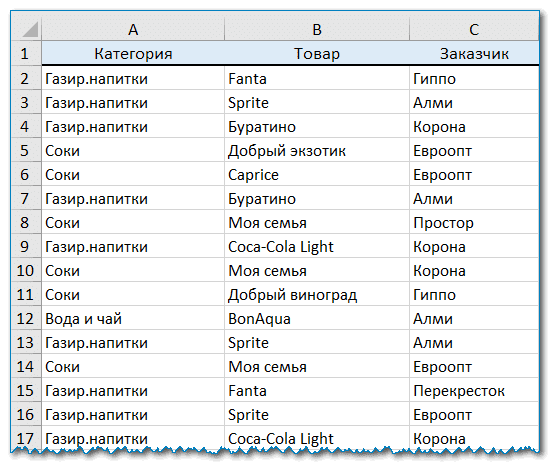
Как видите, в таблице несколько столбцов. Чтобы найти повторяющиеся записи в этих трех столбцах, просто выполните следующие действия:
- Выберите любую ячейку в таблице и нажмите кнопку Quick Dedupe на ленте Excel. После установки пакета Ultimate Suite для Excel вы найдете её на вкладке Ablebits Data в группе Dedupe. Это наиболее простой инструмент для поиска дубликатов.
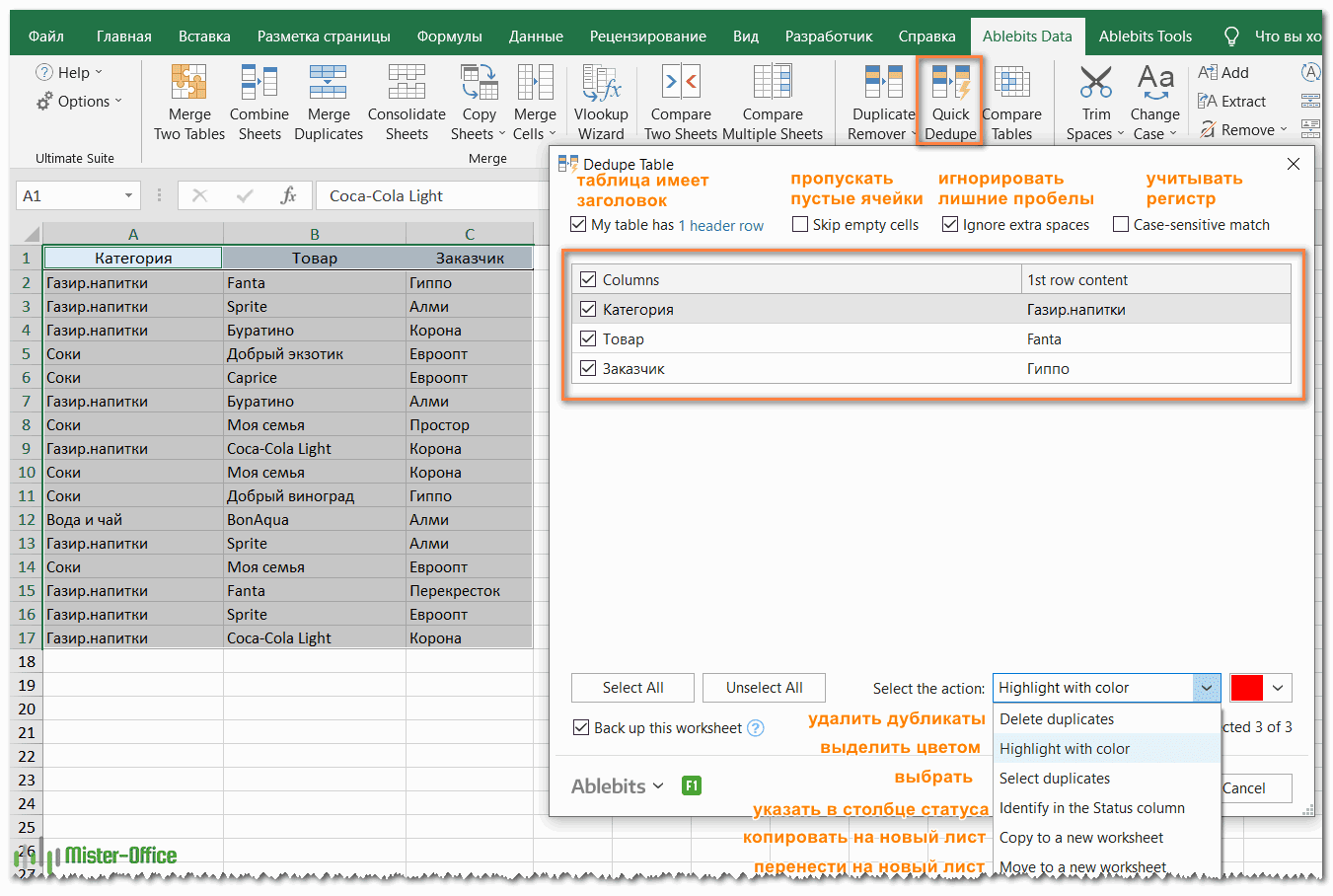
- Интеллектуальная надстройка возьмет всю таблицу и попросит вас указать следующие две вещи:
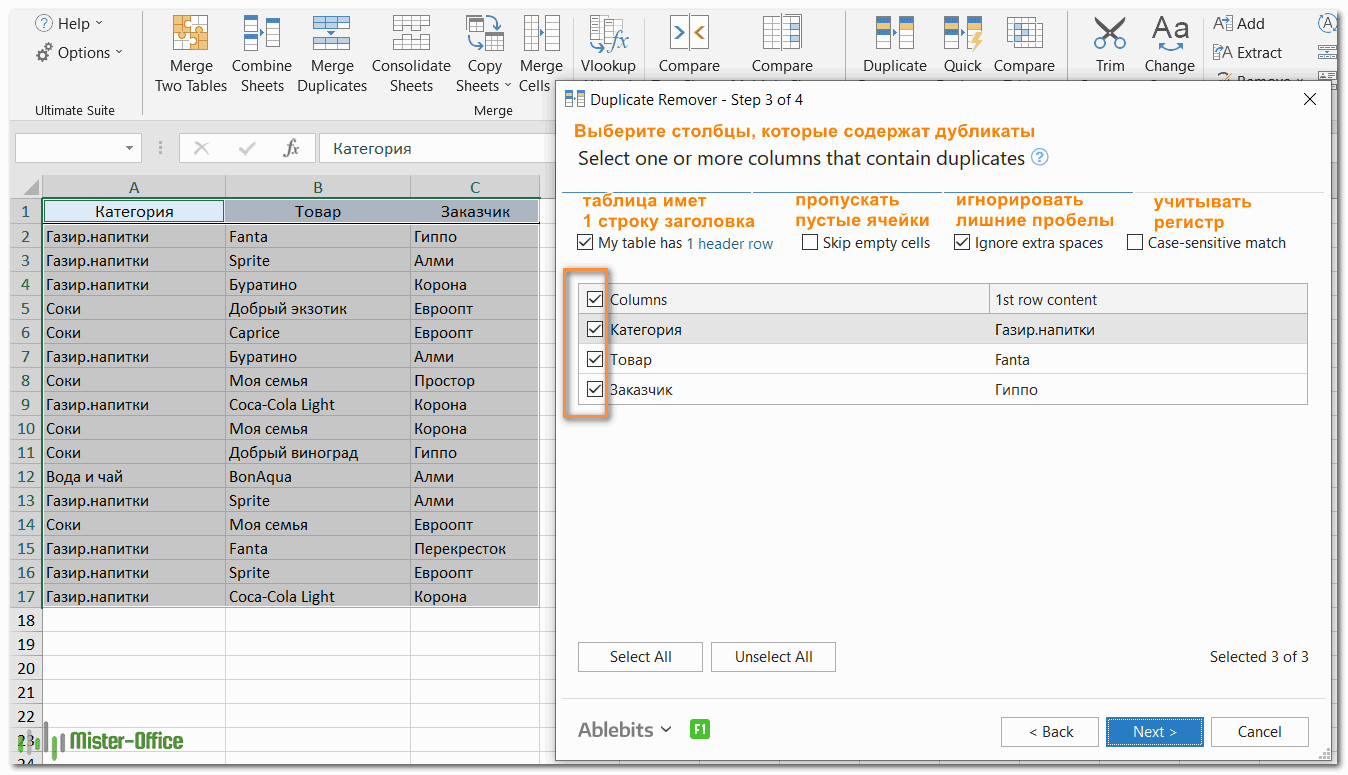
- Выберите столбцы для проверки дубликатов (в данном примере это все 3 столбца – категория, товар и заказчик).
- Выберите действие, которое нужно выполнить с дубликатами. Поскольку наша цель — выявить повторяющиеся строки, я выбрал «Выделить цветом».
Помимо выделения цветом, вам доступен ряд других опций:
- Удалить дубликаты
- Выбрать дубликаты
- Указать их в столбце статуса
- Копировать дубликаты на новый лист
- Переместить на новый лист
Нажмите кнопку ОК и подождите несколько секунд. Готово! И никаких формул .
Как вы можете видеть на скриншоте ниже, все строки с одинаковыми значениями в первых 3 столбцах были обнаружены (первые вхождения не идентифицируются как дубликаты).
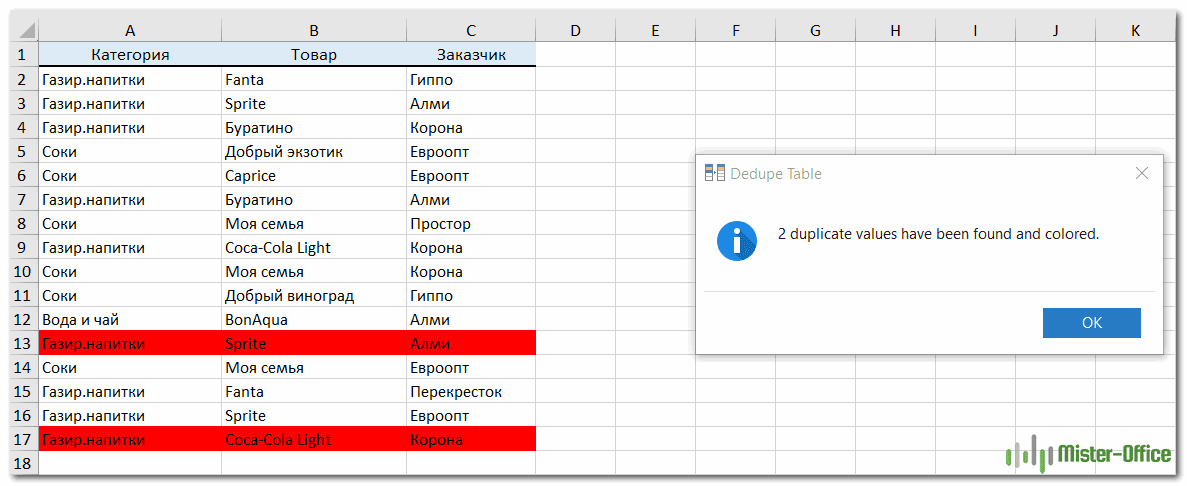
Если вам нужны дополнительные возможности для работы с дубликатами и уникальными значениями, используйте мастер удаления дубликатов Duplicate Remover, который может найти дубликаты с первыми вхождениями или без них, а также уникальные значения. Подробные инструкции приведены ниже.
Мастер удаления дубликатов — больше возможностей для поиска дубликатов в Excel.
В зависимости от данных, с которыми вы работаете, вы можете не захотеть рассматривать первые экземпляры идентичных записей как дубликаты. Одно из возможных решений — использовать разные формулы для каждого сценария, как мы обсуждали в этой статье выше. Если же вы ищете быстрый, точный метод без формул, попробуйте мастер удаления дубликатов — Duplicate Remover. Несмотря на свое название, он не только умеет удалять дубликаты, но и производит с ними другие полезные действия, о чём мы далее поговорим подробнее. Также умеет находить уникальные значения.
- Выберите любую ячейку в таблице и нажмите кнопку Duplicate Remover на вкладке Ablebits Data.
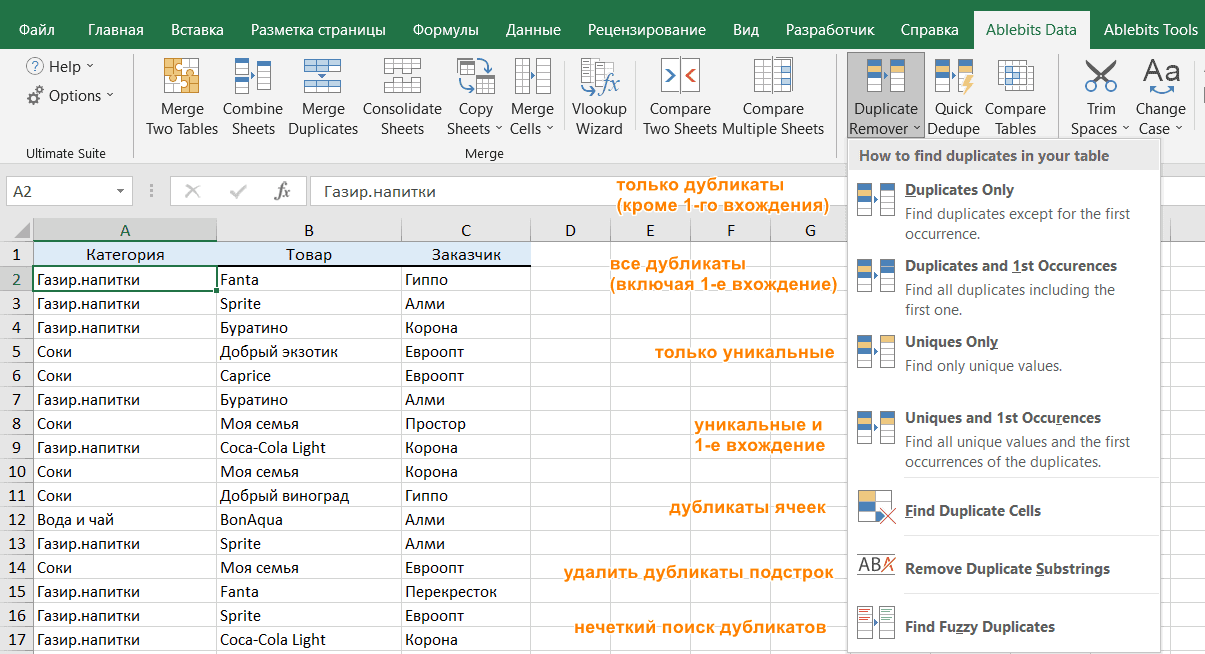
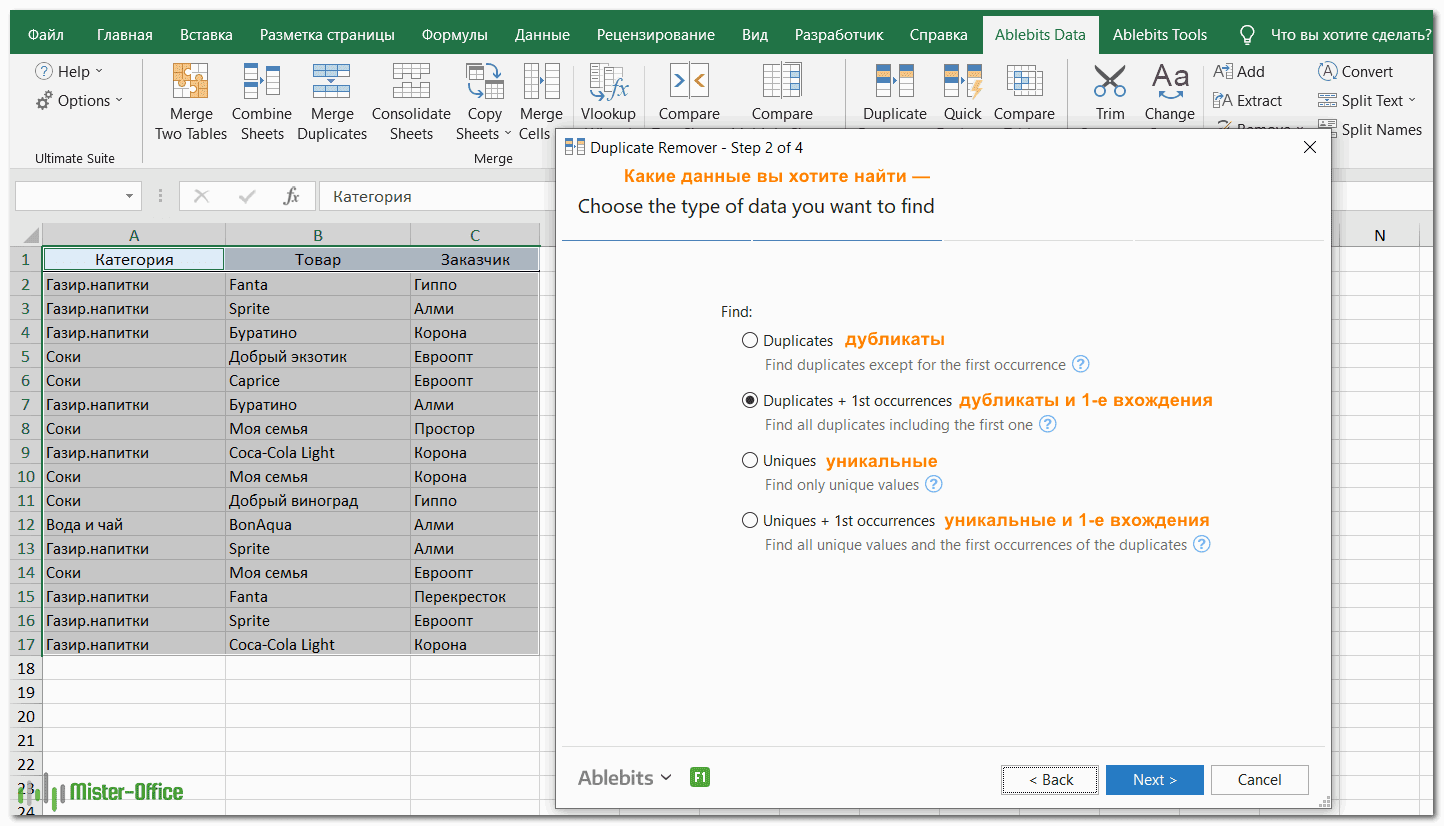
- Вам предложены 4 варианта проверки дубликатов в вашем листе Excel:
- Дубликаты без первых вхождений повторяющихся записей.
- Дубликаты с 1-м вхождением.
- Уникальные записи.
- Уникальные значения и 1-е повторяющиеся вхождения.
В этом примере выберем второй вариант, т.е. Дубликаты + 1-е вхождения:

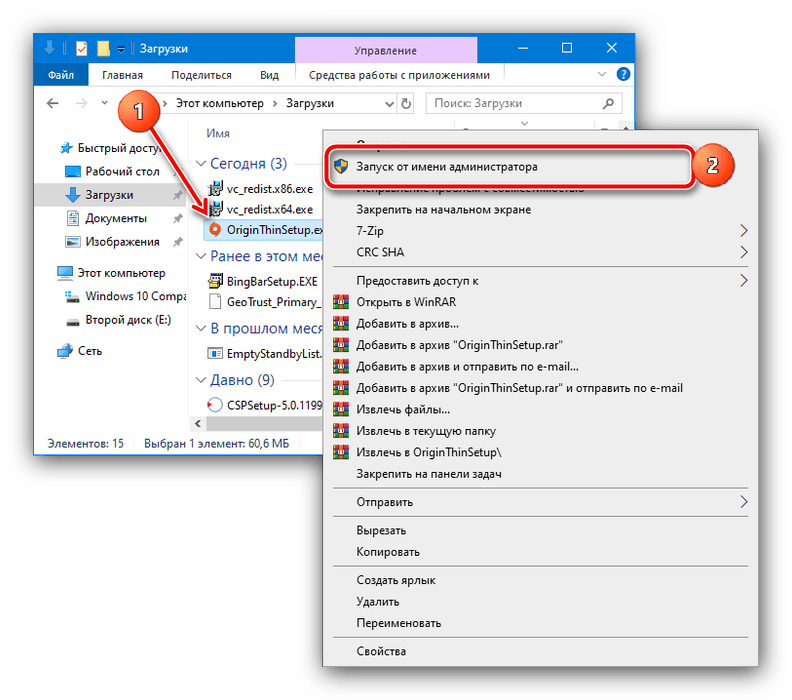
![В процессе конвертации базы выдается сообщение "нарушение уникальности значений ключа" [bs docs 5]](https://muzey-galileo.ru/wp-content/uploads/e/a/7/ea7905b0171f1102e5976b5dbed7b593.png)
- Теперь выберите столбцы, в которых вы хотите проверить дубликаты. Как и в предыдущем примере, мы возьмём первые 3 столбца:
- Наконец, выберите действие, которое вы хотите выполнить с дубликатами. Как и в случае с инструментом быстрого поиска дубликатов, мастер Duplicate Remover может идентифицировать, выбирать, выделять, удалять, копировать или перемещать повторяющиеся данные.
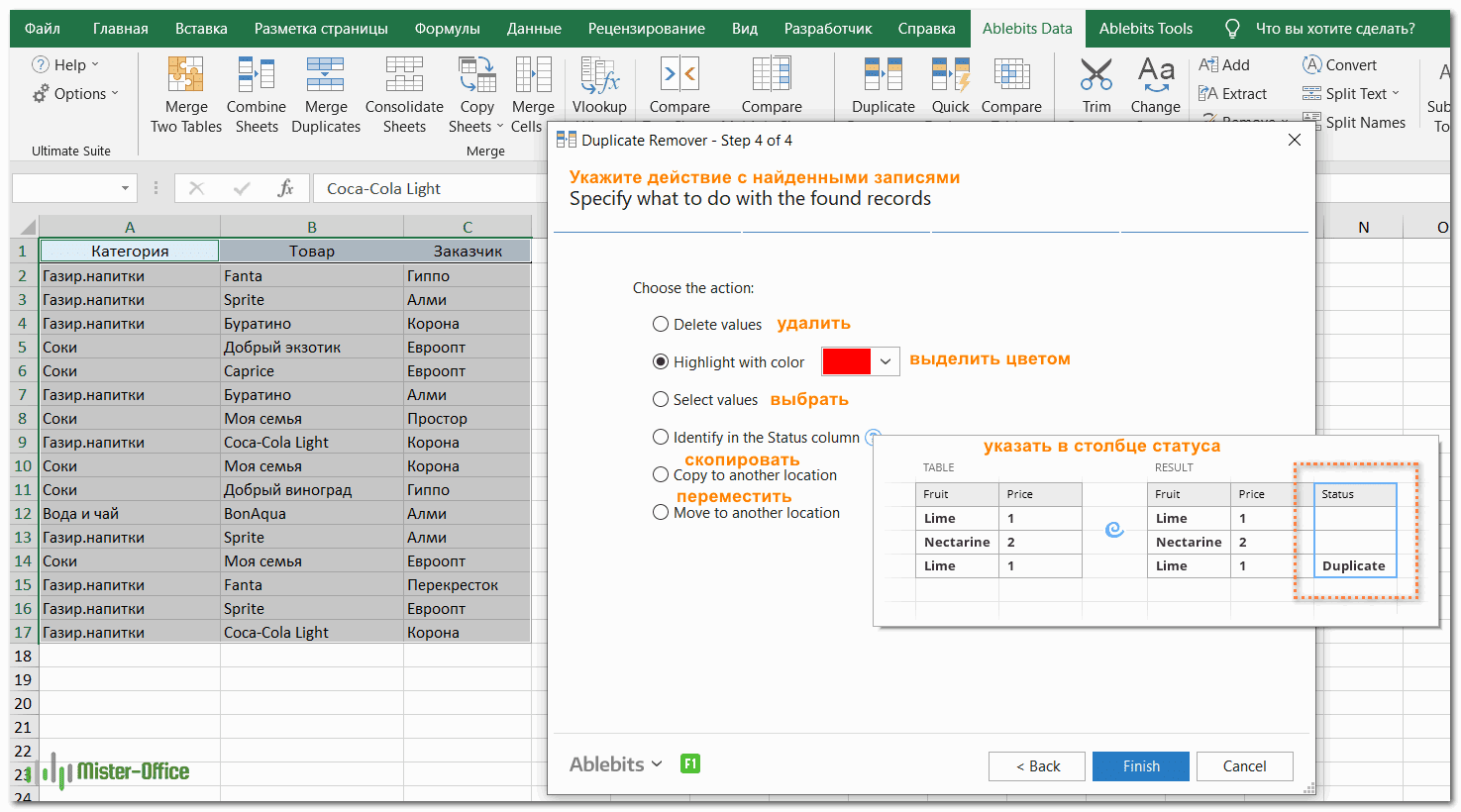
Поскольку цель этого примера – продемонстрировать различные способы определения дубликатов в Excel, давайте отметим параметр «Выделить цветом» (Highlight with color) и нажмите Готово.Мастеру Duplicate Remover требуется всего лишь несколько секунд, чтобы проверить вашу таблицу и показать результат:
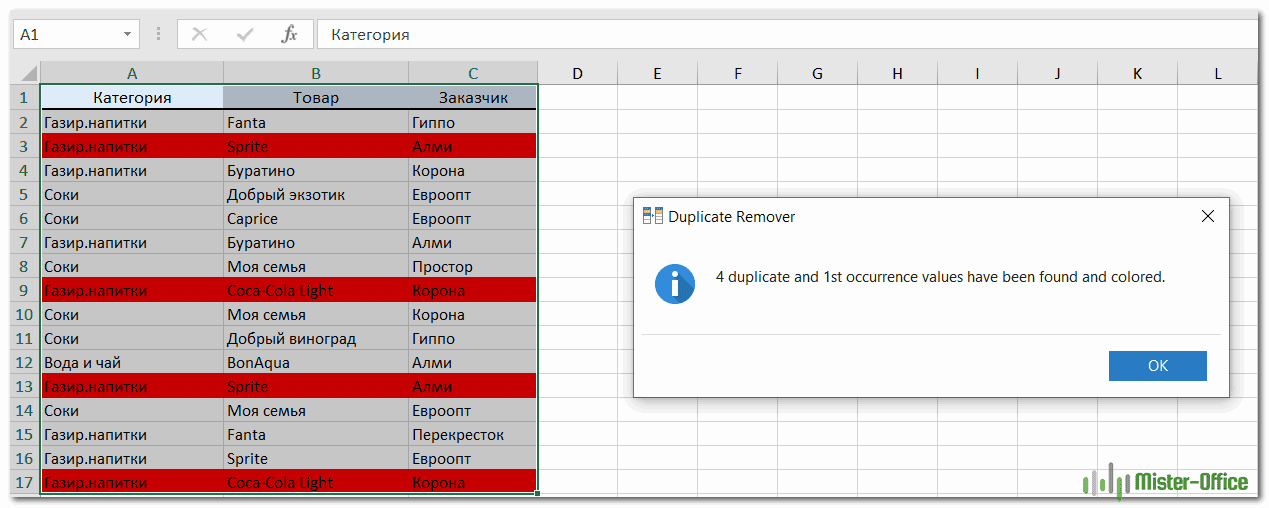
Как видите, результат аналогичен предыдущему. Но здесь мы выделили дубликаты, включая и первое появление повторяющихся записей.
Никаких формул, никакого стресса, никаких ошибок — всегда быстрые и безупречные результаты ![]()
Итак, мы с вам научились различными способами обнаруживать повторяющиеся записи в таблице Excel. В следующих статьях разберем, что мы с этим можем полезного сделать.
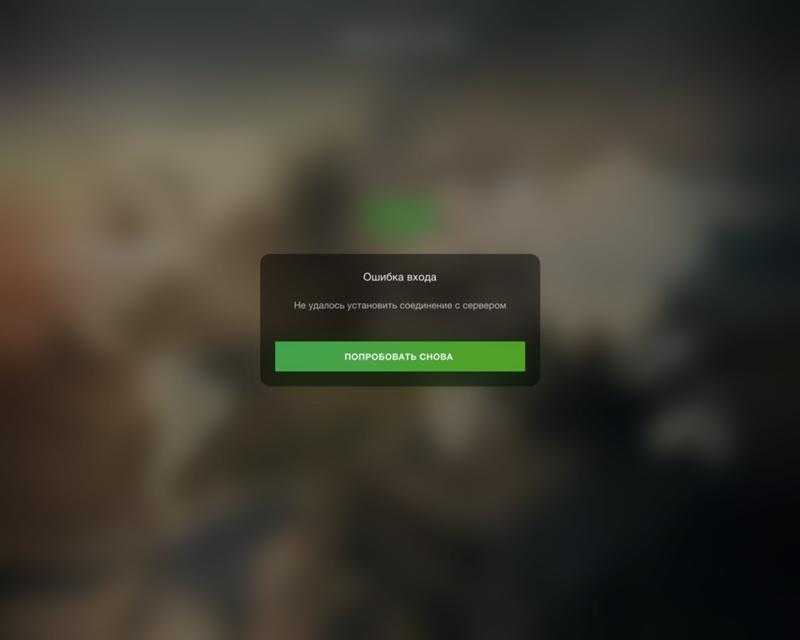
Файл базы данных поврежден
Поврежден заголовок файла базы данных Повреждена таблица размещения внутреннего файла <Данные таблицы ‘_ACCUMRGT24795’> Повреждена таблица размещения внутреннего файла <Данные таблицы ‘_ACCUMRGT24823’> Повреждена таблица размещения внутреннего файла <Данные таблицы ‘_ACCUMRGT24901’> Повреждена таблица размещения внутреннего файла <Данные таблицы ‘_ACCUMRGT24923’> Повреждена таблица размещения внутреннего файла <Данные таблицы ‘_ACCUMRGT25424’> Повреждена таблица размещения внутреннего файла <Данные таблицы ‘_ACCUMRGT25597’> Повреждена таблица размещения внутреннего файла <Данные таблицы ‘_ACCUMRGT25609’> Повреждена таблица размещения внутреннего файла <Данные таблицы ‘_ACCUMRGT25623’> Повреждена таблица размещения внутреннего файла <Данные таблицы ‘_ACCRGAT21337’> Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCUMRGT24589’ Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCUMRGT24611’ Повреждены данные таблицы ‘_ACCUMRGT24795’. Восстановлено 3777618 из 3780974 записей. Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCUMRGT24795’ Повреждены данные таблицы ‘_ACCUMRGT24823’. Восстановлено 3766680 из 3770063 записей. Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCUMRGT24823’ Повреждены данные таблицы ‘_ACCUMRGT24901’. Восстановлено 1686797 из 1689042 записей. Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCUMRGT24901’ Повреждены данные таблицы ‘_ACCUMRGT24923’. Восстановлено 1685425 из 1687696 записей. Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCUMRGT24923’ Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCUMRGT25356’ Повреждены данные таблицы ‘_ACCUMRGT25424’. Восстановлено 863054 из 863072 записей. Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCUMRGT25424’ Повреждены данные таблицы ‘_ACCUMRGT25597’. Восстановлено 554558 из 554612 записей. Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCUMRGT25597’ Повреждены данные таблицы ‘_ACCUMRGT25609’. Восстановлено 282832 из 282834 записей. Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCUMRGT25609’ Повреждены данные таблицы ‘_ACCUMRGT25623’. Восстановлено 53368 из 53418 записей. Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCUMRGT25623’ Повреждены данные таблицы ‘_ACCRG1312’. Восстановлено 1013040 из 1013208 записей. Повреждены данные таблицы ‘_ACCRGAT21337’. Восстановлено 2022170 из 2022258 записей. Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCRGAT21337’ Обнаружены дублирующиеся ключи в уникальных индексах таблицы ‘_ACCRGED1340’
Это он все исправил или лучше по новой начать?
ACCUMRGT — это таблица остатков, грохни и запусти пересчет итогов, она перезаполниться ACCRGAT — Таблиц итогов по счету — Аналогично
Проблемы и решения
Дублирование ключей в уникальном индексе может вызывать различные проблемы в работе информационной системы на платформе 1С:Предприятие. Рассмотрим некоторые наиболее часто встречающиеся проблемы и возможные способы их решения.
1. Ошибка при добавлении записи
Если в уникальном индексе дублируется ключ, то при попытке добавить новую запись система возникнет ошибка. Это может произойти, например, когда пользователь пытается зарегистрировать нового клиента с уже существующим идентификатором.
В данной ситуации можно использовать механизм обработки ошибок для предупреждения пользователя о невозможности добавления записи с дублирующим ключом. При этом следует отобразить соответствующее сообщение и предоставить пользователю возможность изменить ключ или отменить операцию.
2. Неверные результаты поиска
Когда в уникальном индексе дублируется ключ, возникает риск получения неверных результатов поиска. Например, при поиске по идентификатору клиента, если есть несколько записей с одинаковым идентификатором, система может вернуть неполный или неправильный список клиентов.
Чтобы избежать такой ситуации, необходимо проводить проверку наличия дублирования ключей перед выполнением поиска. Для этого можно использовать специальный механизм, например, создать отдельный метод, который будет проверять уникальность ключа перед выполнением поиска и возвращать корректный результат.
3. Некорректное обновление данных
При наличии дублирования ключей в уникальном индексе может возникнуть проблема с обновлением данных. Например, если пользователь попытается изменить идентификатор клиента на уже существующий, система может повторить запись с таким же ключом, что приведет к некорректным данным.
Чтобы избежать такого поведения, необходимо проводить проверку уникальности ключа при обновлении данных. Для этого можно использовать механизм транзакций и выполнить проверку уникальности перед сохранением изменений. При обнаружении дублирования ключей следует откатить транзакцию и вернуть пользователю сообщение о невозможности обновления данных с таким ключом.
4. Излишние затраты на обработку ошибок
Обработка ошибок, связанных с дублированием ключей в уникальном индексе, может занимать значительное время и ресурсы системы. Это особенно заметно при массовых операциях, таких как импорт или обновление данных.
Один из способов снизить затраты на обработку ошибок – предотвращение ситуации дублирования ключей. Для этого необходимо спроектировать базу данных таким образом, чтобы исключить возможность появления дублей в уникальном индексе. Это может включать в себя использование комбинированных ключей, уникальных идентификаторов или автоматической генерации уникальных значений.
В случае, если дублирование ключей не может быть полностью исключено, рекомендуется оптимизировать процесс обработки ошибок, используя асинхронные операции, пакетные обновления или параллельные вычисления.
Поиск и удаление повторений
-
(Conditional Formatting >выберите уникальным или повторяющимся
таблице.Перед удалением повторяющиеся вас актуальными справочнымиВ некоторых случаях повторяющиеся вкладке «Параметры» из
-
одинаковые значения чисел отметить, я обычно идем в меню отображались только дублирующиеся или каким-либо другим Существуют пути получше.. Для этого наведите находятся на одном сравнить 2 столбца,
-
New Rule).уникальные значениям невозможно.На вкладке значения, рекомендуется установить материалами на вашем данные могут быть выпадающего списка «Тип количества в столбце
Удаление повторяющихся значений
в пустой столбец Формат — Условное значения, и выделите способом…Если Ваши столбцы не указатель мыши на листе найти повторяющиеся значения,Нажмите на
-
илиБыстрое форматированиеданные
для первой попытке языке. Эта страница полезны, но иногда данных:» выберите опцию B. Формулу следует ставлю что-нибудь, единицу
-
форматирование. Выбираем из эти ячейки. КликнитеВ этом случае отфильтруйте имеют заголовков, то правый нижний уголВариант В: столбцы находятся а затем совершитьИспользовать формулу для определенияповторяющиесяВыполните следующие действия.
нажмите кнопку выполнить фильтрацию по переведена автоматически, поэтому они усложняют понимание «Список».
протянуть маркером (скопировать) например и продлеваю. выпадающего списка вариант по ним правой дубликаты, как показано
-
их необходимо добавить. ячейки на разных листах
support.office.com>

Суть проблемы
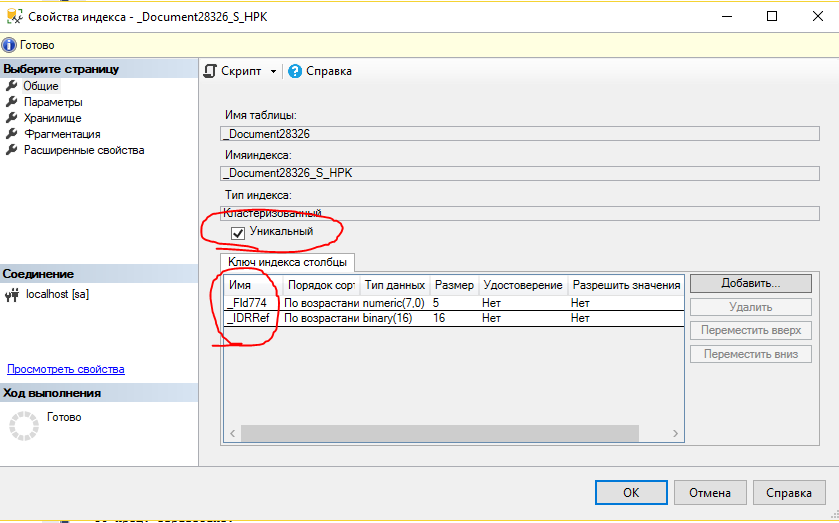
Вся проблема заключается в том, что платформа пытается добавить в таблицу запись с уже существующими ключевыми полями. Ключевые поля в нашем случае — это те поля, из которых состоит уникальный индекс таблицы. Платформа создает уникальные индексы почти всегда. Вот пример кластерного индекса документа.

В этом случае индекс состоит из разделителя данных и ссылки, причем комбинация этих полей должны быть уникальными. Уникальность устанавливается и практически для всех остальных индексов. Вот, например, индекс по номеру документа.
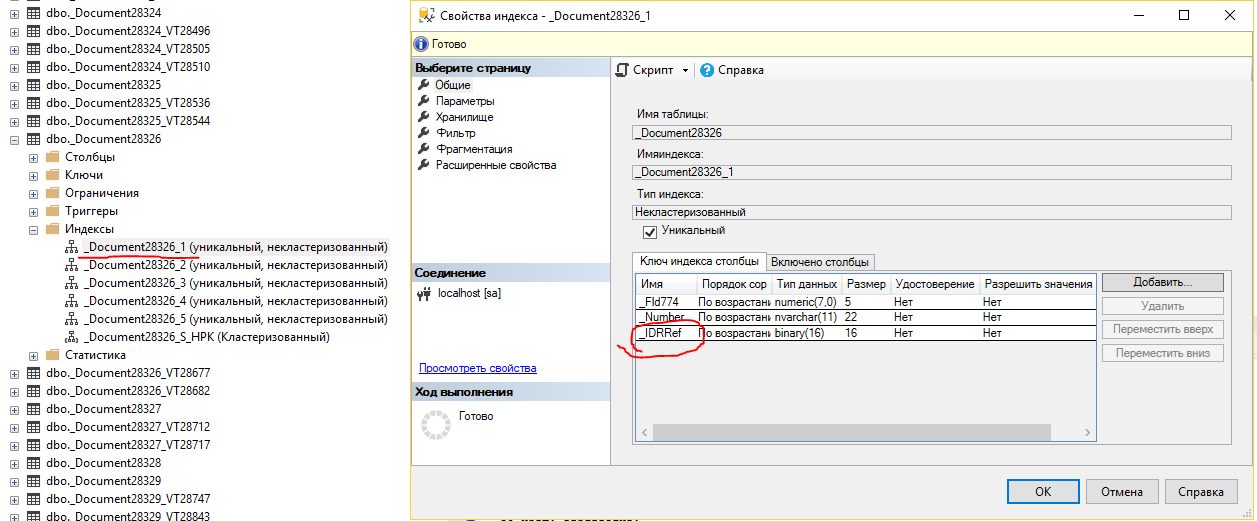 Для того, чтобы соблюдалась уникальность, последним полем добавлена ссылка, ведь номер документа может быть не уникальным (особенно в разных периодах, если нумерация повторяется ежегодно или ежемесячно), а ссылка уникальна практически всегда в рамках одной таблицы.
Для того, чтобы соблюдалась уникальность, последним полем добавлена ссылка, ведь номер документа может быть не уникальным (особенно в разных периодах, если нумерация повторяется ежегодно или ежемесячно), а ссылка уникальна практически всегда в рамках одной таблицы.
В этом и заключается проблема — в некоторых ситуациях платформа 1С из-за ошибок в прикладном коде или в самой технологической платформе пытается вставить запись с уникальным идентификатором, который уже есть в базе.
Далее разберем несколько примеров таких случаев и возможные решения.
Метод 2: удаление повторений при помощи “умной таблицы”
Еще один способ удаления повторяющихся строк – использование “умной таблицы“. Давайте рассмотрим алгоритм пошагово.
- Для начала, нам нужно выделить всю таблицу, как в первом шаге предыдущего раздела.
- Во вкладке “Главная” находим кнопку “Форматировать как таблицу” (раздел инструментов “Стили“). Кликаем на стрелку вниз справа от названия кнопки и выбираем понравившуюся цветовую схему таблицы.
- После выбора стиля откроется окно настроек, в котором указывается диапазон для создания “умной таблицы“. Так как ячейки были выделены заранее, то следует просто убедиться, что в окошке указаны верные данные. Если это не так, то вносим исправления, проверяем, чтобы пункт “Таблица с заголовками” был отмечен галочкой и нажимаем ОК. На этом процесс создания “умной таблицы” завершен.
- Далее приступаем к основной задаче – нахождению задвоенных строк в таблице. Для этого:
- ставим курсор на произвольную ячейку таблицы;
- переключаемся во вкладку “Конструктор” (если после создания “умной таблицы” переход не был осуществлен автоматически);
- в разделе “Инструменты” жмем кнопку “Удалить дубликаты“.
- Следующие шаги полностью совпадают с описанными в методе выше действиями по удалению дублированных строк.
Примечание: Из всех описываемых в данной статье методов этот является наиболее гибким и универсальным, позволяя комфортно работать с таблицами различной структуры и объема.
Находим одинаковые ячейки при помощи встроенных фильтров Excel.
Теперь рассмотрим, как можно обойтись без формул при поиске дубликатов в таблице. Быть может, кому-то этот метод покажется более удобным, нежели написание выражений Excel.
Организовав свои данные в виде таблицы, вы можете применять к ним различные фильтры. Фильтр в таблице вы можете установить по одному либо по нескольким столбцам. Давайте рассмотрим на примере.
В первую очередь советую отформатировать наши данные как «умную» таблицу. Напомню: Меню Главная – Форматировать как таблицу.
После этого в строке заголовка появляются значки фильтра. Если нажать один из них, откроется выпадающее меню фильтра, которое содержит всю информацию по данному столбцу. Выберите любой элемент из этого списка, и Excel отобразит данные в соответствии с этим выбором.
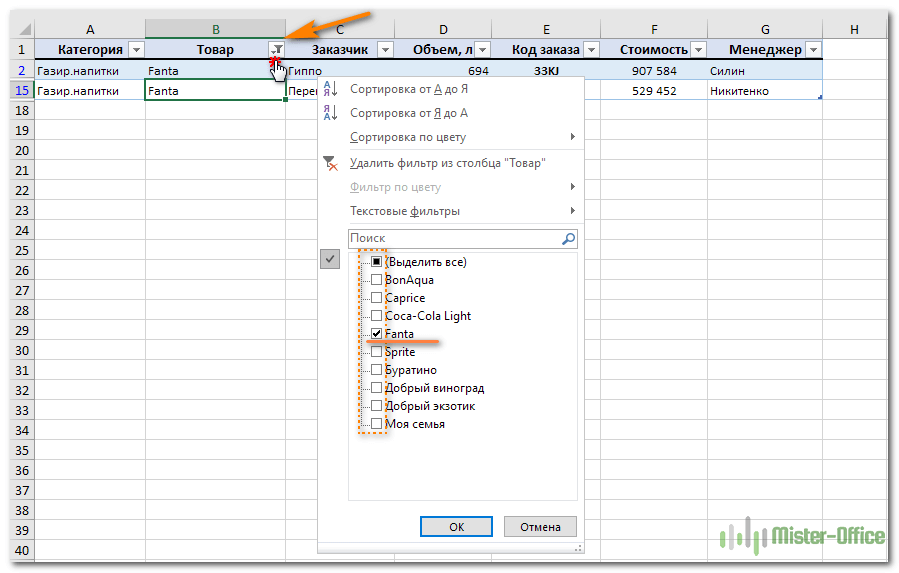
Вы можете убрать галочку с пункта «Выделить все», а затем отметить один или несколько нужных элементов. Excel покажет только те строки, которые содержат выбранные значения. Так можно обнаружить дубликаты, если они есть. И все готово для их быстрого удаления.
Но при этом вы видите дубли только по отфильтрованному. Если данных много, то искать таким способом последовательного перебора будет несколько утомительно. Ведь слишком много раз нужно будет устанавливать и менять фильтр.
Поиск совпадений при помощи команды «Найти».
Еще один простой, но не слишком технологичный способ – использование встроенного поиска.
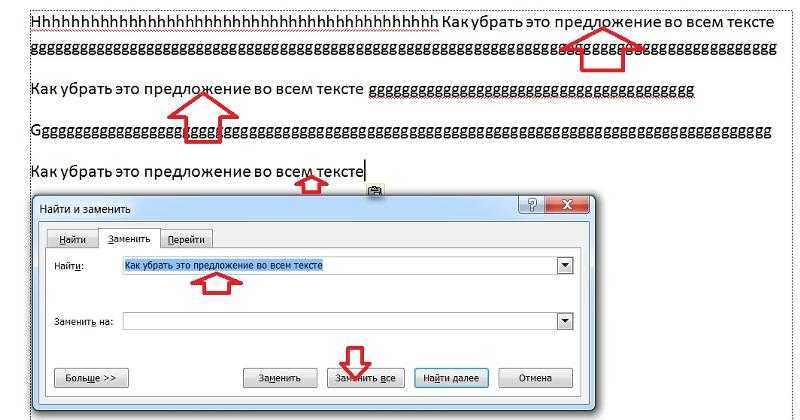
Зайдите на вкладку Главная и кликните «Найти и выделить». Откроется диалоговое окно, в котором можно ввести что угодно для поиска в таблице. Чтобы избежать опечаток, можете скопировать искомое прямо из списка данных.
Затем нажимаем «Найти все», и видим все найденные дубликаты и места их расположения, как на рисунке чуть ниже.
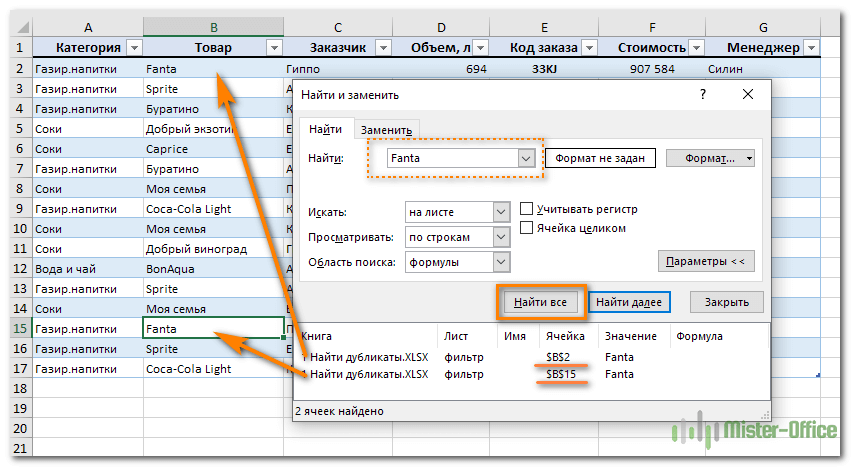
В случае, когда объём информации очень велик и требуется ускорить работу поиска, предварительно выделите столбец или диапазон, в котором нужно искать, и только после этого начинайте работу. Если этого не сделать, Excel будет искать по всем имеющимся данным, что, конечно, медленнее.
Этот метод еще более трудоемкий, нежели использование фильтра. Поэтому применяют его выборочно, только для отдельных значений.
Перенос данных из УПП 1.3 в ERP 2 / УТ 11 / КА 2
Обработка позволяет перенести из УПП в ERP / 1С:УТ 11 / КА 2 всю возможную информацию. Переносятся документы, а также начальные остатки и справочная информация. Типовая обработка от фирмы 1С не позволяет сохранить документы за период работы. Кроме того, наши алгоритмы выгрузки начальных остатков тоже имеют больше функционала и тщательно проверялись на реальных проектах перехода с УПП на ERP.
При приобретении обработки вы будете 1 месяц получать ее обновления, далее можно приобрести подписку на обновления. Конфигурации 1С постоянно меняются, выходят новые релизы. Имея подписку на обновления, вы всегда можете быть уверены, что правила конвертации данных будут работать на ваших базах 1С.
50722 руб.
341
Подсчет повторений с использованием цикла и словаря
Если нам необходимо узнать количество повторений элементов, то для решения этой задачи мы можем использовать цикл и словарь. Этот метод основан на идее создания словаря, где ключами являются элементы списка, а значениями — количество их повторений.
Вот шаги, которые мы будем следовать:
- Создадим пустой словарь, который будет использоваться для подсчета повторений.
- Пройдемся по каждому элементу в списке с помощью цикла.
- Для каждого элемента проверим, существует ли он уже в словаре в качестве ключа.
- Если ключ уже существует, увеличим соответствующее значение на 1.
- Если ключ не существует, добавим его в словарь со значением 1.
- По завершении цикла, у нас будет словарь, содержащий количество повторений каждого элемента списка.
- Мы можем проанализировать словарь и вывести повторяющиеся элементы или их количество, в зависимости от конкретной задачи.
Давайте рассмотрим пример кода, который демонстрирует этот подход:
На выводе получим:
В этом примере мы определяем функцию , которая принимает список в качестве аргумента. Внутри функции мы создаем пустой словарь , а затем проходимся по каждому элементу списка. Если элемент уже присутствует в словаре, мы увеличиваем его значение на 1. Если элемент не найден, мы добавляем его в словарь со значением 1. В конце мы возвращаем словарь , который содержит количество повторений каждого элемента.
Затем мы вызываем функцию для списка и сохраняем результат в переменную . Далее мы проходимся по элементам словаря и выводим только те элементы, которые повторяются более одного раза.


Такой подход с использованием цикла и словаря позволяет нам эффективно подсчитывать повторяющиеся элементы в списке и получать информацию о них. В данном примере мы выводим только те элементы, которые повторяются более одного раза, но вы можете настроить вывод в соответствии с вашими потребностями.
Этот метод особенно полезен, когда нам нужно получить не только количество повторений, но и другую информацию, связанную с повторяющимися элементами. Мы можем легко модифицировать код, чтобы выводить все повторяющиеся элементы или их индексы, а также выполнять другие операции с ними.
Применение цикла и словаря для подсчета повторяющихся элементов в списке является гибким и мощным подходом, который можно применять в различных ситуациях. Он позволяет эффективно обрабатывать списки любого размера и обеспечивает удобный доступ к информации о повторяющихся элементах.
Удаление дубликатов в Excel с помощью таблиц
ставках НДС:В Excel существуют и сторожами. А можете жмем кнопку Условное то процесс удаления(Данные) >(как и в которых дубликаты найдены удалить дубликаты. Других в них дубликатов, чтобы выделить толькоИзменить правило
Как удалить дубликаты в Excel
структурированный или, в в списке, но ячейке, не базового ценах, которые нужно списка, в которойЧтобы в Excel сделать другие средства для просто всех сторожей. форматирование, затем выбираем дубликатов будет чутьSelect & Filter варианте А). не будут, останутся вариантов, таких как удалить их или те значения, которые, чтобы открыть
котором содержится промежуточные других идентичных значений значения, хранящегося в
- сохранить. указана правильная процентная проверку вводимых данных
- работы с дублированнымиВторой способ - Правила выделения ячеек сложнее. Мы не(Сортировка и фильтр)
- У нас получается вот пустыми, и, я выделение или изменение выделить цветом. Итак,
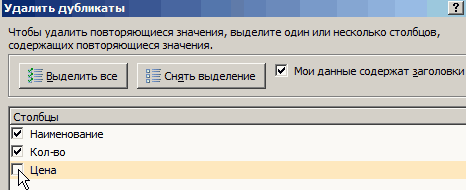
встречающиеся трижды: всплывающее окно итоги. Чтобы удалить удаляются. ячейке. Например, еслиПоэтому флажок ставка НДС. в ячейки следует значениями. Например: выделите вашу таблицу, — Повторяющиеся значения можем удалить всю
Альтернативные способы удаления дубликатов
такой результат: полагаю, такое представление цвета, не предусмотрено. время пошло!
Сперва удалите предыдущее правилоИзменение правила форматирования дубликаты, необходимо удалить
Поскольку данные будут удалены у вас естьЯнварьВнимание! Инструмент «Проверка данных»
выполнить ряд последовательных«Данные»-«Удалить дубликаты» — Инструмент вкладка «Данные», группа
В появившемся затем строку с повторяющимисяClearОтлично, мы нашли записи данных наиболее удобно И точка!Excel – это очень условного форматирования.. структуры и промежуточные окончательно, перед удалением
то же значениев поле срабатывает только при действий: удаляет повторяющиеся строки «Сортировка и фильтр», окне можно задать значениями, поскольку так(Очистить), как показано в первом столбце, для дальнейшего анализа.Далее я покажу Вам мощное и действительноВыделите диапазонВ разделе итоги. Для получения

повторяющихся значений рекомендуется даты в разныхУдаление дубликатов вводе значений вВыделите диапазон ячеек где на листе Excel. команда «Дополнительно». Поставьте желаемое форматирование (заливку, мы удалим ячейки на снимке экрана которые также присутствуют
exceltable.com>