
Вынести файлы базы TempDB на отдельный диск.
Служебная база данных TempDB используется всеми базами сервера для хранения, промежуточных расчетов, временных таблиц, версий строк при использовании RCSI и многих других вещей. Обычно обращений к этой базе очень много, и если она будет лежать на медленных дисках, это может замедлить работу системы.
Рекомендуется хранить базу TempDB на отдельном диске для повышения производительности работы системы.
Для переноса базы TempDB на отдельный диск необходимо:
Запустить Management Studio и подключиться к нужному серверу
Создать окно запроса и выполнить скрипт:
ALTER DATABASE tempdb
MODIFY FILE (NAME = tempdev, FILENAME = ‘Новый_Диск:\Новый_Каталог\tempdb.mdf’)
ALTER DATABASE tempdb
MODIFY FILE (NAME = templog, FILENAME = ‘Новый_Диск:\Новый_Каталог\templog.ldf’)
Перезапустить MS SQL Server
Если 1С тормозит …
Если 1С тормозит, значит, системе нужна оптимизация. С чего начать оптимизацию мы рассказали в статьях «Введение в APDEX – с чего начинают оптимизацию профессионалы» и «Как использовать подсистему «Оценка производительности» для измерения времени операций (статья + видео)».
Но если Вы хотите подойти к вопросу оптимизации комплексно, рекомендуем наш курс «Ускорение и Оптимизация 1С. Базовый курс».
На курсе Вы научитесь:
- Оценивать состояние системы в любой момент времени.
- Быстро находить причины замедления в программном коде.
- Настраивать регламентные задания для обслуживания базы на MS SQL.
- Видеть динамику производительности за определенный период.
- Устранять ожидания на блокировках.
- Решать проблемы со взаимоблокировками.
Программа, стоимость и условия:
Ускорение и оптимизация работы 1С, Базовый курс
- 16 учебных часов видео
- 50 практических заданий
- 3 месяца поддержки и доступа к ответам на вопросы
- Пожизненный доступ к видео-урокам и учебным материалам
Смотреть
Проверить, сколько ядер используют MS SQL Server и 1С
Если у Вас мощный сервер — это еще не значит, что Вы используете его на полную мощность.
Причины у этого могут быть разные. Например, такое происходит, если при настройке окружения не учли ограничения MS SQL или приобрели не ту версию 1С.
Давайте разберем подробнее оба случая.
Проверить, сколько ядер используют MS SQL Server
Разные версии MS SQL имеют разные ограничения
Их важно учитывать при настройке окружения. Например, версия MS SQL Standard 2016 может использовать либо 4 сокета, либо 24 ядра, исходя из того, чего меньше (данные из таблицы на сайте Microsoft Ignite)
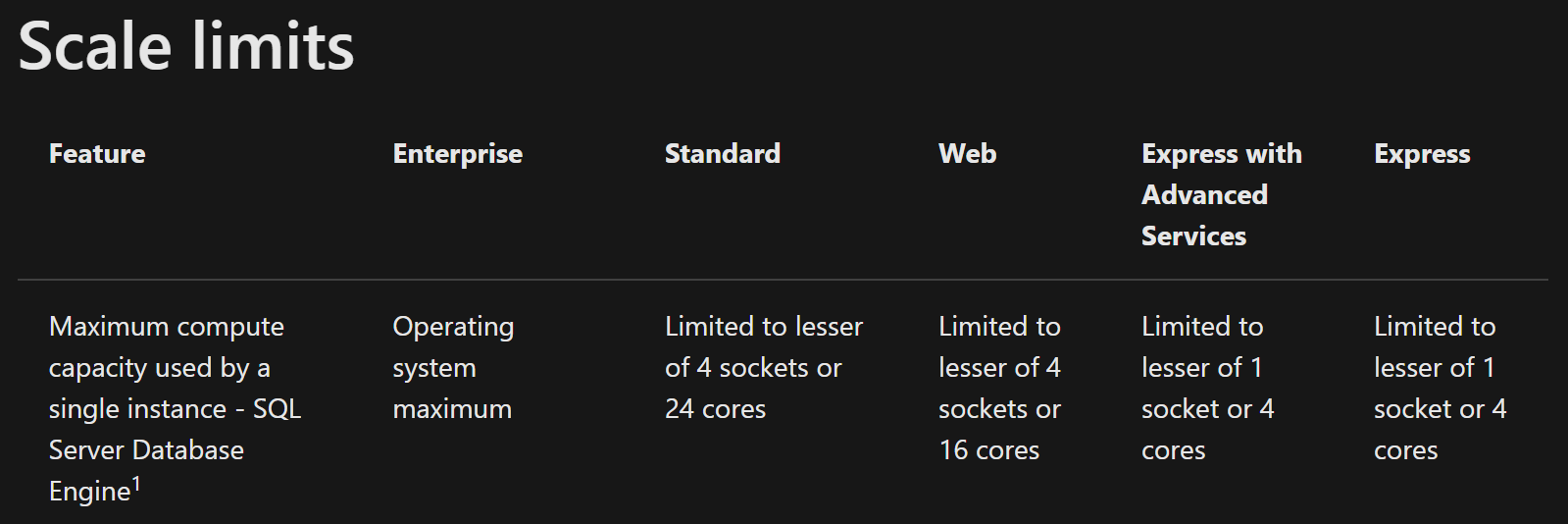
Рисунок 3. Ограничения разных версий MS SQL Server
Формулировка очень важна: выбирается именно меньшее, а не большее.
Допустим, у Вас есть многопроцессорный сервер, т. е. сервер с несколькими сокетами. На нем размещена виртуальная машина, на которую установлен сервер MS SQL. При этом в виртуальной машине настроено 12 процессоров по 2 ядра. Сколько ядер будет использовать MS SQL?
MS SQL будет использовать 4 процессора, следовательно, всего 8 ядер из 24. Остальные ядра будут не загружены. Правильным решением будет настроить на виртуальной машине 4 процессора по 6 ядер на каждом, либо 2 по 12 ядер. В этом случае MS SQL сможет использовать все 24 ядра.
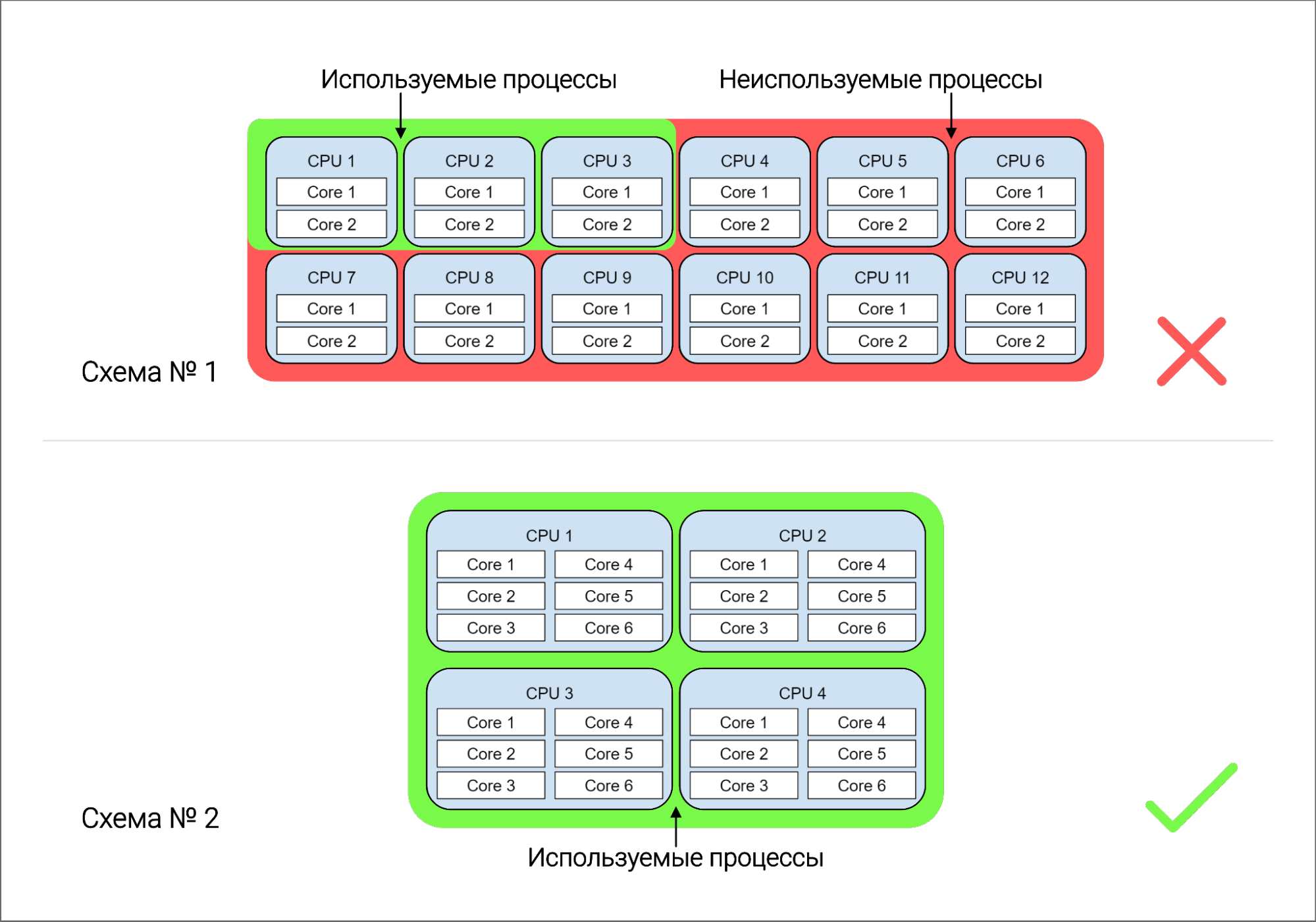
Рисунок 4. Неправильная и правильная настройки процессоров. В схеме № 1 MS SQL использует только 4 процессора из 12, а в схеме № 2 — все 12
Вот пример неверной настройки, когда вместо 12 ядер в виртуальной машине было настроено 12 сокетов — по одному ядру на каждый сокет. Видно, что загружены только 4 ядра из 12.
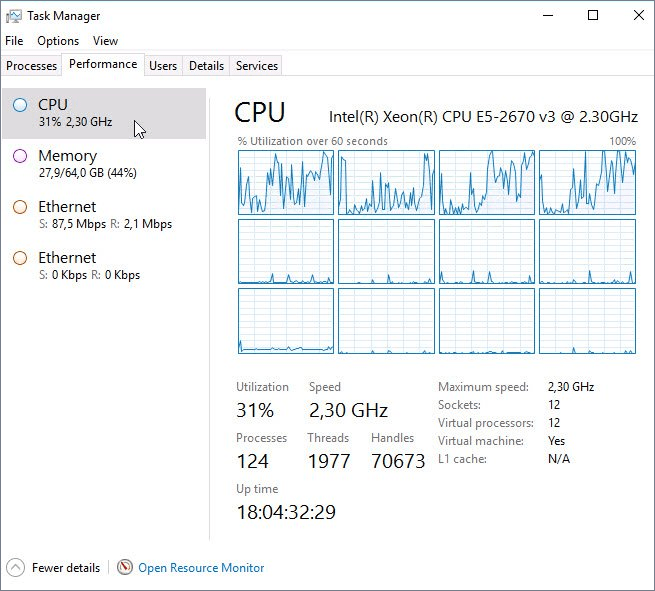
Рисунок 5. Неравномерная загрузка ядер при неправильной настройке виртуальной машины
Чтобы узнать, сколько логических процессоров (ядра, в том числе и гиперпоточные) задействует Ваш экземпляр MS SQL, следует выполнить следующий запрос
select * from sys.dm_os_schedulers where status = ‘VISIBLE ONLINE’ and is_online = 1
Рисунок 6. Отображение реального количества логических процессоров, используемых MS SQL Server
Еще имеет смысл поискать в логах MS SQL сообщения следующего характера:
SQL Server detected 1 sockets with 4 cores per socket and 8 logical processors per socket, 8 total logical processors; using 8 logical processors based on SQL Server licensing. This is an informational message; no user action is required.
Из этого текста следует, что все хорошо — число найденных ядер равно числу используемых.
Но сообщение может быть иным, например:
SQL Server detected 4 sockets with 12 cores per socket and 12 logical processors per socket, 48 total logical processors; using 24 logical processors based on SQL Server licensing. This is an informational message; no user action is required.
В этом случае половина процессорных мощностей простаивает.
Найти такие сообщения в логах можно с помощью следующего запроса:
EXEC sys.xp_readerrorlog 0, 1, N’detected’, N’socket’;
Проверить, сколько ядер используют 1С
Важно помнить, что у 1С тоже есть ограничения по количеству используемых ядер. Например, версия ПРОФ может использовать только 12 ядер и, если поставить ее на 24-ядерный сервер, то половина процессорных мощностей будет простаивать
Если на сервере больше 12 ядер и Вы хотите, чтобы 1С использовала их все, необходимо приобрести версию КОРП.
Oracle
Редакторы блокируют редакторов: при выполнении операции редактирования одного пространственного объекта или группы объектов, например при их перемещении или изменении их атрибутов, СУБД блокирует строки их таблиц. Объекты будут заблокированы до тех пор, пока вы не сохранитесь или не завершите сессию редактирования, не сохраняясь. Соответственно, любой редактируемый пространственный объект или запись остается заблокированным на протяжении всего сеанса редактирования.
Когда два пользователя пытаются редактировать один и тот же объект в одно и то же время, объект блокируется, когда первый пользователь завершает операцию. Эта блокировка будет удерживаться, даже если этот пользователь начал работать совсем с другими объектами. Объекты будут заблокированы до тех пор, пока вы не сохранитесь или не завершите сессию редактирования, не сохраняясь.Следовательно, любой объект или запись, которые вы будете редактировать, будут заблокированы на период вашей сессии редактирования.
Пока этот объект будет заблокирован, второй пользователь будет пытаться изменить его. Сессия второго пользователя ArcMap ждет прекращения блокировки, отображая уже знакомые песочные часы. Песочные часы будут продолжать отображаться до тех пор, пока блокировка не будет снята или когда истечет время ожидания выполнения запроса на снятие блокировки (настройка в используемой СУБД, в которой устанавливается ее значение), в зависимости от того, что произойдет раньше



В этот момент песочные часы у второго пользователя исчезнут и он сможет выполнить свою операцию редактирования.(Обратите внимание, что при этом он отменит редактирование первого пользователя.) (Обратите внимание, что при этом он отменит редактирование первого пользователя.) Редакторы не блокируют пользователей, считывающих данные:
Два пользователя одновременно редактируют одно и то же.
- Пользователи изменили записи в своих текущих сеансах редактирования.
- Каждый из пользователей пытается изменить запись, уже измененную другим пользователем.
- У первого пользователя, который попытается изменить заблокированную строку, будут отображены песочные часы, поскольку его сессия ArcMap ожидает снятия блокировки.
Как только второй пользователь попытается изменить строку, заблокированную первым пользователем, возникнет ситуация, которая известна как взаимоблокировка (или тупик) (deadlocking): ситуация, при которой оба пользователи заблокировали друг друга. СУБД выведет для одного из них сообщение о необходимости в произведении отката транзакций, чтобы другой пользователь смог продолжить работу. Пользователь, транзакции которого были отменены, должен повторно внести все изменения, сделанные после момента последнего сохранения.
Редакторы не блокируют пользователей: пользователи, производящие запись в базу данных, не могут помешать другим пользователям считывать те же самые данные, независимо от установленного уровня изоляции. У пользователей, которые считывают заблокированные данные, это выглядит так, как будто это произошло до начала выполнения текущей транзакции.
Разнести файлы данных mdf и файлы логов ldf на разные физические диски.
В этом случае работа с файлами может идти не последовательно, а практически параллельно, что повышает скорость работы дисковых операций. Лучше всего для этих целей подходят диски SSD.
Для переноса файлов необходимо:
-
Запустить Management Studio и подключиться к нужному серверу
-
Открыть свойства нужной базы и выбрать закладку Файлы
-
Запомнить имена и расположение файлов
-
Отсоединить базу, выбрав через контекстное меню Задачи – Отсоединить
-
Поставить флаг Удалить соединения и нажать Ок
-
Открыть Проводник и переместить файл данных и файл журнала на нужные носители
-
В Management Studio открыть контекстное меню сервера и выбрать пункт Присоединить базу
-
Нажать кнопку Добавить и указать файл mdf с нового диска
-
В нижнем окне сведения о базе данных в строке с файлом лога нужно указать новый путь к файлу журнала транзакций и нажать Ок
Немного о параллелизме
Параллелизм – это возможность выполнения запросов сервером СУБД в нескольких потоков. Если MS SQL Server работает на многопроцессорной машине, то «компонент Database Engine определяет оптимальную степень параллелизма, то есть количество процессоров, задействованных для выполнения одной инструкции, для каждого из планов параллельного выполнения. MS SQL Server определяет уровень параллелизма до начала выполнения запроса без необходимости перекомпиляции плана его выполнения, и один и тот же запрос в разное время в зависимости от условий на момент начала его выполнения может быть выполнен с разным уровнем параллелизма или вообще последовательно» (из документации к MS SQL Server).
По умолчанию в настройках SQL Server параллелизм не ограничен и потенциально для выполнения запроса могут использоваться все ядра всех процессоров (max degree of parallelism= 0). Соответственно, чтобы ограничить количество потоков, на которые будет распараллеливаться запрос настройка max degree of parallelism должна быть отличной от нуля. А верхний предел диапазона значений – это количество всех ядер CPU.
Кроме MaxDOP (max degree of parallelism) есть вторая важная настройка – cost threshold for parallelism, которая отвечает за порог срабатывания параллелизма. Или, по-другому, стоимостная оценка, при которой оптимизатор запросов начинает анализировать предварительный план в случае последовательного запуска и параллелизма, и выбирает, что ему выгоднее использовать. Чем выше значение этого параметра, тем меньшее количество запросов будет параллелиться или, правильнее сказать, тем большему количеству запросов будет запрещено параллелиться. Это нужно для того, чтобы найти некий баланс, золотую середину между количеством запросов без параллелизма и с параллелизмом, иначе на некоторых системах можно легко вогнать процессор «в банку» и/или словить огромное количество блокировок на параллелизме.
Включить механизм версионирования в MS SQL для 8.2
Все еще много конфигураций работает в режиме совместимости с 8.2 или на самой платформе 8.2.
В управляемом режиме блокировок в 8.2 читающие запросы в транзакции устанавливают блокировки. Из-за этого при параллельной работе нескольких пользователей пишущие транзакции блокируют читающие, что приводит к излишним ожиданиям на блокировках.
Если у Вас такая конфигурация и в ней используется режим управляемых блокировок, необходимо обязательно в MS SQL включить режим версионирования READ_COMMITTED_SNAPSHOT.
Это можно сделать с помощью следующей команды:
ALTER DATABASE ИмяБазы SET READ_COMMITTED_SNAPSHOT ON
При этом в базе не должно быть пользователей, иначе команда не будет выполнена.
После выполнения команды поведение системы будет аналогично 8.3: читающие запросы в транзакции не будут блокировать данные, следовательно, количество ожиданий на блокировках сократится.
Проблема в том, что периодически, например при обновлении, платформа будет возвращать прежний режим. Необходимо постоянно следить за тем, чтобы данный режим был включен. Например, можно сделать регламентное задание на MS SQL, которое будет регулярно выполнять вышеприведенных запрос.
Включить возможность мгновенной инициализации файлов (Database instant file initialization)
Это позволяет ускорить работу таких операций как:
-
Добавление файлов, журналов или данных в существующую базу данных
-
Увеличение размера существующего файла (включая операции автоувеличения)
-
Восстановление базы данных или файловой группы
Для включения настройки:
-
На компьютере, где будет создан файл резервной копии, откройте приложение Local Security Policy (secpol.msc)
-
Разверните на левой панели узел Локальные политики, а затем кликните пункт Назначение прав пользователей
-
На правой панели дважды кликните Выполнение задач по обслуживанию томов
-
Нажмите кнопку «Добавить» пользователя или группу и добавьте сюда пользователя, под которым запущен сервер MS SQL Server
-
Нажмите кнопку Применить
Настройка Windows для установки сервера 1С
Для корректной работы базы данных должна быть выполнена настройка sql для 1с наряду с общими настройками системы в соответствии с рекомендациями разработчика платформы 1С:Предприятие. Эти действия можно разбить по шагам:
- Если не требуется иного, произвести выравнивание секторов дискового пространства (граница 1024 Кб) и произвести форматирование с размером блока 64 Кб (официальная инструкция Microsoft: https://technet.microsoft.com/en-us/library/dd758814.aspx).
- В локальных политиках безопасности разрешить выполнение задач по обслуживанию томов пользователю, от чьего имени будет запускаться сервер базы данных (официальная инструкция Microsoft: https://msdn.microsoft.com/en-us/library/ms175935.aspx). Для проверки корректности работы службы нужно создать новую базу данных размером не менее 5 Гб, если отклик получился моментальный – все работает правильно, тестовую базу можно удалять.
Разрешение выполнения задач в ПБ для томов
- Если сервер 1С: Предприятие и СУБД 1С SQL установлены раздельно, то в локальных политиках безопасности разрешить блокировку страниц в памяти пользователю, от чьего имени будет запускаться сервер базы данных (https://msdn.microsoft.com/ru-ru/library/ms190730(v=sql.120).aspx).
Разрешение выполнения задач в ПБ для блокировки страниц
- Перевести план электропитания в режим «Высокая производительность» (Панель управления – Электропитание).
- Открыть свойства папки с файлами данных (DATA) и папки журнала (LOG), перейти в раздел расширенных настроек и убедиться, что сжатие файлов данных отключено (галочка снята).
Снятие флага сжатия данных
- Если на сервере настроено автоматическое резервное копирование, то добавить в исключения менеджера файлы СУБД MSSQL (они не должны быть заняты менеджером копирования).
На этом настройку системы можно считать законченной, однако также необходима настройка MSSQL для 1с в соответствии со следующими рекомендациями (все действия осуществляются через менеджер СУБД под пользователем sa):
- Если сервер 1С и MSSQL установлены раздельно, то необходимо открыть свойства СУБД и в разделе «Память» (Memory) выставить верхнюю (половина от всей имеющейся) и нижнюю границы (Общая – 1024*Общая/16384 (Мб) – формула означает, что остается 1 Гб на работу системы на каждые 16 Гб общего объема). В случае совместной установки необходимо опытным путем вычислить и учесть объем ОЗУ, требуемый для работы платформы 1С.
Вычисление и установка объема ОЗУ
- Если сервера БД и 1С установлены раздельно, то в свойствах «Процессоры» (Processors) СУБД необходимо выставить приоритет для базы данных («Boost SQL Server priority»).
Установка флага приоритета для БД
- На вкладке настройки баз данных («Database settings») можно (и желательно) настроить пути, используемые по умолчанию. Следует помнить, что официальные инструкции Microsoft рекомендуют хранить файлы БД и журналов на разных дисковых пространствах, при этом к первым время отклика должно быть не более 20 мс, а ко вторым – не более 5 мс (мс – миллисекунды).
Поля ввода значения путей по умолчанию
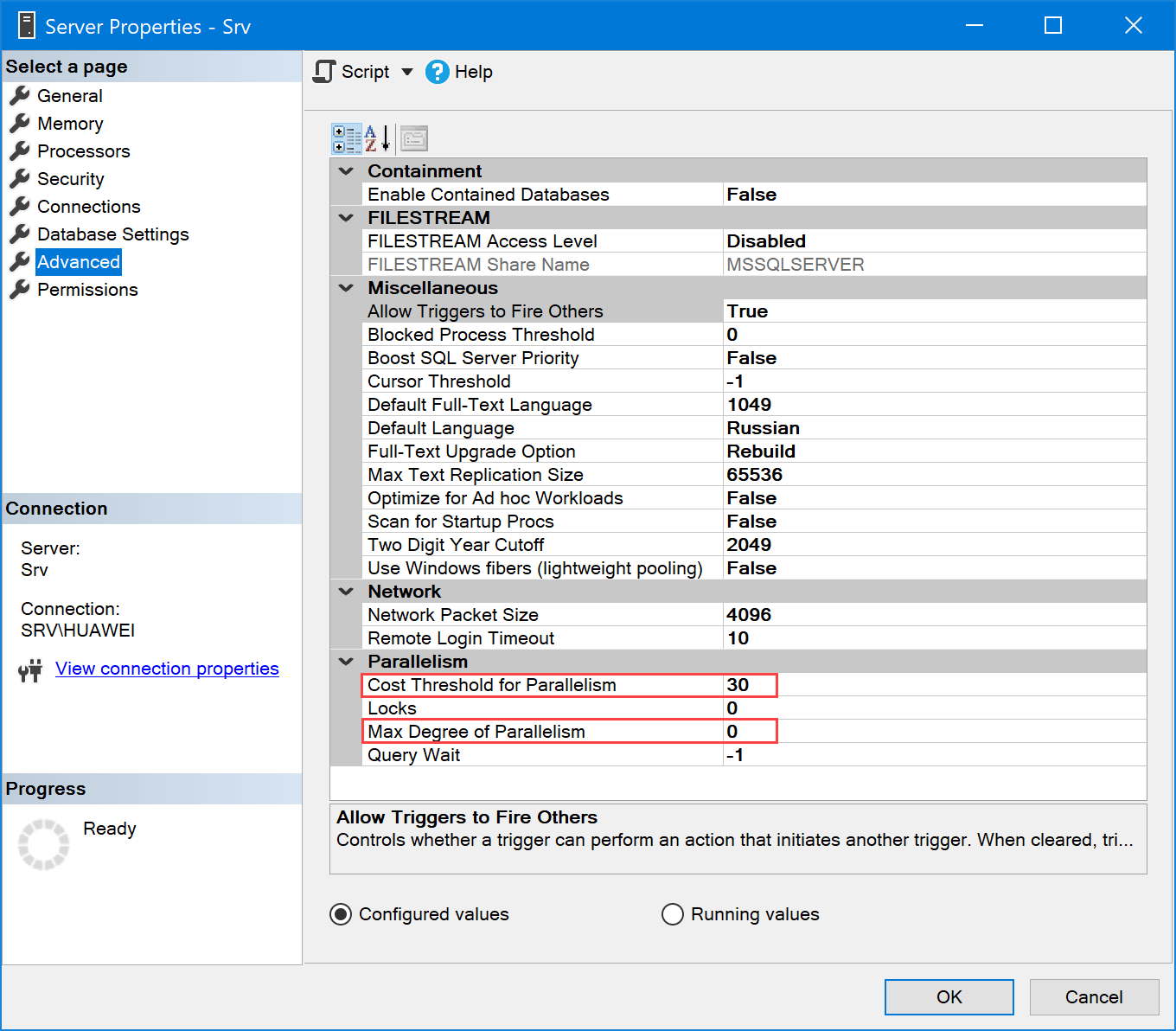
- На вкладке «Расширенные» («Advanced») установить значение параметра «Max degree of parallelism» равным 1.
Установка параметра значения
Убрать лишнее
Этот способ ускорения системы заключается в том, чтобы отключить все, что не используется, но забирает ресурсы. Особенно это касается типовых конфигураций.
Кому-то покажется, что это совет от капитана Очевидность. Но стоит отбросить сарказм — есть множество баз, в которых работают все стандартные регламентные задания и оставлены настройки по умолчанию.
Проведите ревизию включенных регламентных заданий. Действительно ли все эти задания нужны? Может, часть относится к механизмам, которые Вы не используете?
Ситуация усугубляется, когда на сервере расположено большое количество баз: часть из них для разработки, часть — для тестов, еще часть кто-то когда-то зачем-то создал. В каждой из них выполняются задания, обновление полнотекстового поиска и т. д.
Все это никак не помогает производительности Вашей системы, поэтому стоит отключить все лишнее.
Первое, на что нужно обратить внимание при ревизии — это полнотекстовый поиск. Если он не используется, тогда лучше его отключить, чтобы он зря не «съедал» ресурсы системы
(нажмите, чтобы увеличить картинку)
Рисунок 11. Отключение полнотекстового поиска 1С
Если же полнотекстовый поиск используется, тогда стоит оставить свойство «Полнотекстовый поиск» в значении Использовать только для тех реквизитов, где он действительно необходим. У остальных объектов следует его отключить.






Многоверсионный контроль параллелизма
Механизмы управления параллелизмом, которые мы представили до сих пор, на самом деле предназначены для разрешения условий гонки между транзакциями путем задержки или завершения соответствующих транзакций для обеспечения сериализуемости транзакций; хотя предыдущие два механизма управления параллелизмом действительно могут принципиально решить проблему сериализуемости параллельных транзакций. но в реальной среде транзакции базы данных в основном доступны только для чтения, а запрос на чтение во много раз превышает запрос на запись.Если перед запросом на запись и запросом на чтение нет механизма управления параллелизмом, то в худшем случае запрос на чтение считывает уже записанные данные, что вполне приемлемо для многих приложений.
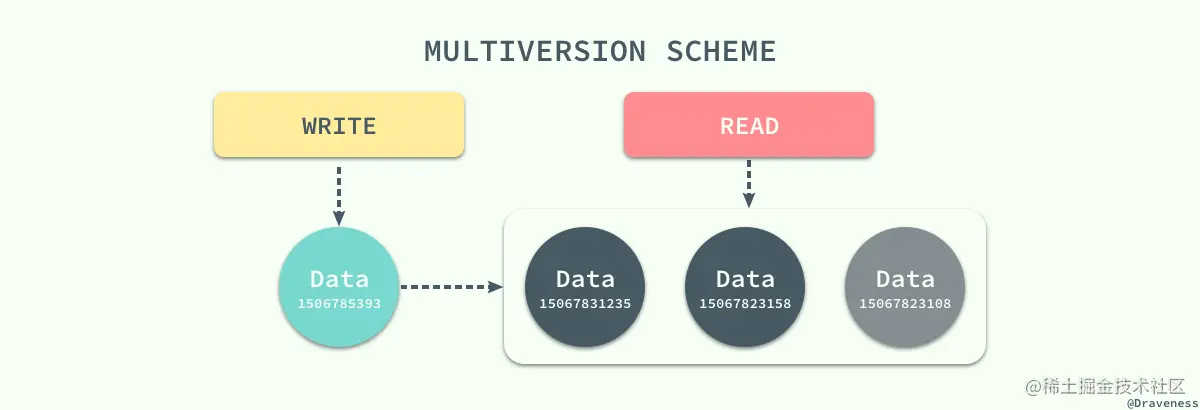
В соответствии с этой основной предпосылкой система базы данных представляет еще один механизм управления параллелизмом —Многоверсионный контроль параллелизма(Multiversion Concurrency Control), каждая операция записи будет создавать новую версию данных, а операция чтения будет выбирать наиболее подходящий результат из ограниченного числа версий данных и возвращать его напрямую; в это время конфликт между операциями чтения и операции записи станут уже не требующими внимания, а управление и быстрая подборка версий данных становится основной проблемой, которую необходимо решить MVCC.
MVCC не является антитезой оптимистического и пессимистического управления параллелизмом, его можно хорошо комбинировать с ними для увеличения параллелизма транзакций.MVCC реализован в самых популярных базах данных SQL MySQL и PostgreSQL, но из-за того, что они реализуют пессимистическую блокировку и оптимистическую блокировку соответственно, поэтому способ реализации MVCC тоже отличается.
MySQL и MVCC
Многоверсионный протокол двухфазной блокировки (Multiversion 2PL), реализованный в MySQL, сочетает в себе преимущества MVCC и 2PL.Каждая версия строки данных имеет уникальную временную метку.При запросе на чтение транзакции программа базы данных будет непосредственно из Возвращает самую большую отметку времени среди нескольких версий элемента данных.

Операция обновления немного сложнее.Транзакция сначала прочитает последнюю версию данных, чтобы вычислить результат обновления данных, а затем создаст новую версию данных.Временная метка новых данных является самой большой версией текущая строка данных.:

Удаление версии данных также выбирается в соответствии с отметкой времени.MySQL будет периодически удалять данные с самой низкой версией из базы данных, чтобы гарантировать отсутствие большого количества устаревшего контента.
PostgreSQL и MVCC
В отличие от использования пессимистического контроля параллелизма в MySQL, в PostgreSQL используется оптимистический контроль параллелизма, что приводит к некоторым отличиям в реализации MVCC в комбинации оптимистичных блокировок.Окончательная реализация называется Multiversion Timestamp Sorting Protocol. Ordering), в этом протоколе всем транзакциям присваивается уникальная временная метка перед выполнением, и каждый элемент данных имеет две временные метки для чтения и записи:
Когда транзакция PostgreSQL отправляет запрос на чтение, база данных напрямую возвращает последнюю версию данных, не блокируясь какой-либо операцией.При выполнении операции записи отметка времени транзакции должна быть больше или равна отметке времени чтения строки данных. , иначе произойдет откат.
Реализация этого MVCC гарантирует, что транзакция чтения никогда не завершится ошибкой и не нужно ждать освобождения блокировки.Для приложений с гораздо большим количеством запросов на чтение, чем запросов на запись, оптимистическая блокировка плюс MVCC может значительно повысить производительность базы данных; хотя этот протокол может обеспечить некоторые очевидные улучшения производительности в некоторых практических ситуациях, он также приводит к двум проблемам: во-первых, каждая операция чтения будет обновлять метку времени чтения, что приводит к двум операциям записи на диск, а во-вторых, между транзакциями. путем отката, поэтому, если вероятность конфликта очень высока или откат обходится дорого, производительность чтения и записи базы данных будет не такой хорошей, как при использовании традиционного метода ожидания блокировки.
Несколько советов по настройке кластера 1С.
Настройки кластера отвечают за настройки всех серверов, принадлежащих настраиваемому кластеру. Кластер — это работа нескольких физических или виртуальных серверов, работающих с одними и теми же информационными базами.
- Интервал перезапуска — отвечает за частоту перезапуска рабочих процессов кластера. Этот параметр необходимо выставлять при круглосуточной работы сервера. Рекомендуется частоту перезапуска связывать с технологическим циклом информационных баз кластера. Обычно это каждые 24 часа (86400 сек). Как известно, рабочие процессы серверов 1С обрабатывают и хранят рабочие данные.
- Автоматический перезапуск был разработан в платформе «для минимизации отрицательных последствий фрагментации и утечки памяти в рабочих процессах». На ИТС есть даже информация о том, как организовать перезапуск рабочих процессов по другим параметрам (объем памяти, занимаемые ресурсы и т.п.).
- Допустимый объем памяти — защищает сервера 1С от перерасхода памяти. При превышении процессом этого объема в интервале превышения допустимого объема, процесс перезапускается. Можно рассчитать, как максимальный размер памяти, занимаемый процессами «rphost» в периоды пиковой нагрузки серверов. Также стоит установить небольшой интервал превышения допустимого объема.
- Допустимое отклонение количества ошибок сервера. Платформа рассчитывает среднее количество ошибок сервера по отношению к числу обращений к серверу в течение 5 минут. Если это отношение превысит допустимое, то рабочий процесс считается «проблемным», и может быть завершен системой, если установлен флаг «Принудительно завершать проблемные процессы».
- Выключенные процессы останавливать через. При превышении допустимого объема памяти, рабочий процесс не завершается сразу, а становится «выключенным», чтобы было время «перенести» рабочие данные без потери на новый запущенный рабочий процесс. Если указан этот параметр, то «выключенный» процесс в любом случае завершится по истечении этого времени. Если наблюдаются «зависшие» рабочие процессы в работе сервера 1С, то можно стоит этот параметр на 2-5 минут.
Результирующие наборы не обновляются
Обновляемый результирующий набор ― это результирующий набор, в котором строки могут быть вставлены, обновлены и удалены. В следующих случаях служба SQL Server не может создать обновляемый курсор и формирует исключение «Результирующий набор не является обновляемым».
| Причина | Описание | Средство |
|---|---|---|
| Инструкция не создается при использовании синтаксиса JDBC 2.0 (или более поздней версии) | В JDBC 2.0 введены новые способы создания инструкций. Если используется синтаксис JDBC 1.0, результирующий набор по умолчанию доступен только для чтения. | Укажите тип результирующего набора и параллелизм при создании инструкции. |
| Инструкция создается при помощи TYPE_SCROLL_INSENSITIVE | SQL Server создает статический курсор моментального снимка. Курсор отключается от строк базовой таблицы, чтобы защитить курсор от обновления строк другими пользователями. | Используйте TYPE_SCROLL_SENSITIVE, TYPE_SS_SCROLL_KEYSET, TYPE_SS_SCROLL_DYNAMIC или TYPE_FORWARD_ONLY с CONCUR_UPDATABLE, чтобы не создавать статического курсора. |
| Конструкция таблицы исключает курсор KEYSET или DYNAMIC | Базовая таблица не содержит уникальных ключей, позволяющих SQL Server уникально идентифицировать строки. | Добавьте уникальные ключи к таблице, чтобы обеспечить уникальную идентификацию каждой строки. |
Настроить параллелизм в MS SQL Server¶
Оставить настройку Max degree of parallelism = 0, но установить настройку Cost threshold for parallelism = 30.
Такая настройка означает, что MS SQL будет самостоятельно решать, сколько потоков использовать для выполнения одного запроса, но распараллеливание будет включаться, только если стоимость плана запроса будет выше 30.
Стоимость плана измеряется в неких условных единицах и отражает, насколько «тяжелым» является запрос для исполнения. Чем выше стоимость, тем сильнее запрос нагружает систему. При настройках по умолчанию параллельность включается, если стоимость плана выше 5. Значение 30 — не какая-то сакральная величина: просто, с точки зрения автора, оно подходит для большинства систем.
Благодаря такой настройке параллельность будет использоваться только для действительно сложных запросов. Запросы полегче продолжат выполняться в один поток — им распараллеливание все равно не дает заметного ускорения.
Следует отметить, что это решение не освобождает от необходимости оптимизировать «тяжелые» запросы, но оно хотя бы не мешает другим операциям выполняться быстро.
Установка cost threshold for parallelism
Warning
Сбросить статистику после изменения настроек
DBCC SQLPERF (N’sys.dm_os_wait_stats’, CLEAR);
GO
Несколько ситуаций, при которых не стоит отключать распараллеливание:
- Описанный в документации случай, когда один запрос при распараллеливании замедляет всех — не самый распространенный паттерн. Чаще неоптимальный запрос выполняется медленно в один поток, хотя мог бы выполняться гораздо быстрее в несколько потоков, при этом несильно загружая процессор.
- Если отключить распараллеливание на уровне сервера, тогда и регламентные операции по умолчанию тоже будут выполняться в один поток. Чтобы этого избежать, нужно указывать настройку распараллеливания (MAXDOP = 0) для регламентного задания дефрагментации/реиндексации, чего многие, к сожалению, не делают.
- Новый механизм реструктуризации работает гораздо быстрее, если включено распараллеливание. Об этом сказано и в документации. Там же предлагается каждый раз перед реструктуризацией включать параллельность, а после обновления — отключать. Но все мы люди, и часто разработчики просто забывают установить параметр в нужное значение. В итоге реструктуризация больших таблиц даже с новым механизмом идет медленно.
- Ожидания CXPACKET зачастую интерпретируются неправильно. Их наличие далеко не всегда говорит о проблемах с распараллеливанием. Если хочется больше узнать об этом, подробности Вы найдете в статье Troubleshooting the CXPACKET wait type in SQL Server.
Что дает параллелизм?
Это фактически линейное ускорение запроса. Например, если в один поток, на одном ядре запрос выполняется за 10 сек., то в десять потоков, на десяти ядрах он выполнится за 1 секунду. Получить десятикратное увеличение, не прибегая к рефакторингу кода – это очень круто. Это самый простой, наименее затратный способ ускорения некоторых (!) запросов. Нет рисков, как при переписывании кода, получить функциональные ошибки, не нужно задействовать ресурсы на тестирование и исправление ошибок.
Ниже приведен скриншот из программы мониторинга Perfeхpert, на котором видно как разные запросы в один и тот же момент времени распараллеливаются на разное количество потоков.
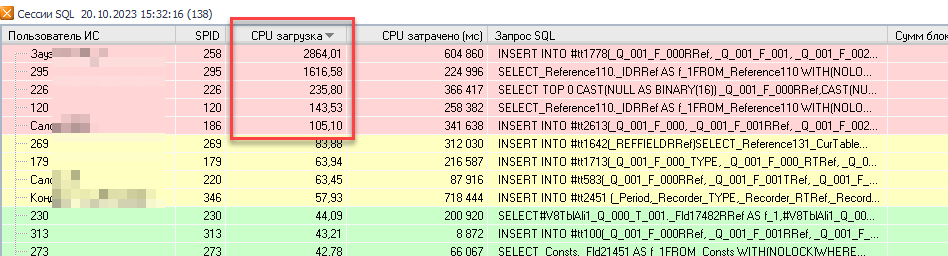
Если в колонке «CPU Загрузка» больше 100%, то значит запрос использует более одного логического ядра процессора.
Кроме того, для серверов СУБД имеет важное значение качественная утилизация ресурсов процессора. Мы встречались неоднократно с ситуациями, когда процессор сервера СУБД «простаивает», недозагружен

При этом жалобы на производительность есть. Такая система явно имеет потенциал для улучшения производительности за счет правильной утилизации CPU.
Пример настройки
Условие задания:
Есть сервер: V81CORA (192.168.1.222), на котором установлен сервер 1С: Предприятия и зарегистрированы две информационные базы: test и test1.
Есть сервер Z3060015, который необходимо использовать для создания отказоустойчивого кластера 1С из двух серверов: V81CORA и Z3060015.
Это наиболее простой случай создания и использования отказоустойчивого кластера серверов 1С предприятия 8.2.
Решение.
- Имеем один сервер V81CORA с единственным рабочим процессом. Все установки – по умолчанию (1540, 1541) На нем зарегистрированы 2 базы 1C.
Свойства рабочего процесса V81CORA 1:
2. На втором сервере (Z3060015) поднимаем сервер 1C: Предприятия с единственным рабочим процессом. На нем нет зарегистрированных информационных баз. Все установки – по умолчанию (1540, 1541).
Разнести файлы данных mdf и файлы логов ldf на разные физические диски.
В этом случае работа с файлами может идти не последовательно, а практически параллельно, что повышает скорость работы дисковых операций. Лучше всего для этих целей подходят диски SSD.
Для переноса файлов необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства нужной базы и выбрать закладку Файлы
Запомнить имена и расположение файлов
Отсоединить базу, выбрав через контекстное меню Задачи – Отсоединить
Поставить флаг Удалить соединения и нажать Ок
Открыть Проводник и переместить файл данных и файл журнала на нужные носители
В Management Studio открыть контекстное меню сервера и выбрать пункт Присоединить базу
Нажать кнопку Добавить и указать файл mdf с нового диска
В нижнем окне сведения о базе данных в строке с файлом лога нужно указать новый путь к файлу журнала транзакций и нажать Ок
Включить возможность мгновенной инициализации файлов (Database instant file initialization)
Это позволяет ускорить работу таких операций как:
-
Создание базы данных
-
Добавление файлов, журналов или данных в существующую базу данных
-
Увеличение размера существующего файла (включая операции автоувеличения)
-
Восстановление базы данных или файловой группы
Для включения настройки:
-
На компьютере, где будет создан файл резервной копии, откройте приложение Local Security Policy (secpol.msc)
-
Разверните на левой панели узел Локальные политики, а затем кликните пункт Назначение прав пользователей
-
На правой панели дважды кликните Выполнение задач по обслуживанию томов
-
Нажмите кнопку «Добавить» пользователя или группу и добавьте сюда пользователя, под которым запущен сервер MS SQL Server
-
Нажмите кнопку Применить
Обзор
Как контролировать параллелизм — одна из самых важных проблем в области баз данных, но до сих пор было много зрелых решений для управления параллелизмом транзакций, и принципы этих решений — это то, что мы хотим представить в этой статье, которая будет представлена в article Три наиболее распространенных механизма управления параллелизмом:

Это пессимистичный контроль параллелизма, оптимистичный контроль параллелизма и многоверсионный контроль параллелизма, среди которых пессимистичный контроль параллелизма на самом деле является наиболее распространенным механизмом контроля параллелизма, то есть блокировками; а оптимистичный контроль параллелизма на самом деле имеет другое название: оптимистичные блокировки, оптимистичные блокировки на самом деле это не настоящая блокировка, мы подробно расскажем о ней в конце статьи; последняя — это многоверсионный контроль параллелизма (MVCC), используемый в сочетании для повышения производительности чтения базы данных.
Поскольку эта статья описывает различные механизмы контроля параллелизма, то он должен быть связан с различными параллельными транзакциями, как работают механизмы, мы проанализируем схематическим образом.
Проверить выполнение регламентных операций СУБД и 1С
Как на СУБД, так и на 1С обязательно должны выполняться регламентные операции. Настройки регламентных операций — тема обширная и выходит за рамки этой статьи
Просто важно помнить, что без регламентных операций производительность системы будет падать
Зачастую о регламентах забывают при апгрейде сервера, обновлениях, смене СУБД или смене паролей для запуска служб MS SQL, поэтому даже если все было настроено, лучше проверить еще раз, что регламентные операции по-прежнему выполняются.
Регламентные операции для СУБД
Для СУБД обязательными являются обновление статистики и дефрагментация/реиндексация индексов.
Обновление статистики — важнейшая регламентная операция. Если статистика не актуальна, то запросы на больших таблицах будут выполняться медленно.




Фрагментация индексов негативно влияет на скорость работы дисковой подсистемы и на объем оперативной памяти. Чем выше фрагментация на диске, тем больший объем оперативной памяти будут занимать данные.
Регламентные операции для 1С
В 1С в первую очередь имеются в виду сдвиг границы и пересчет итогов.
В идеале граница рассчитанных итогов должна быть на конец предыдущего месяца — тогда остатки за предыдущие периоды будут получаться быстро.
Рисунок 9. Установка периода рассчитанных итогов
Не стоит устанавливать период рассчитанных итогов далеко в будущем, иначе любая запись в регистр будет вызывать обновление итогов за все будущие месяцы. Это не только замедлит работу пользователя, но и увеличит время блокировки данных, что может привести к ожиданиям на блокировках.
Пересчет итогов также является важной регламентной операцией. При ее выполнении из таблицы удаляются нулевые итоги, которые могут занимать значительный объем
Также пересчет сворачивает строки, возникающие при работе механизма разделения итогов, что тоже уменьшает размер таблицы.
Полный пересчет итогов на больших базах занимает много времени, поэтому часто его предпочитают вообще не делать. Однако эту операцию необходимо проводить регулярно, чтобы не накапливать большое количество строк с нулевыми итогами. В качестве альтернативы можно выполнять пересчет только текущих итогов — эта операция выполняется гораздо быстрее.